関数リファレンス
関数 (カテゴリー別)
集合の操作
| 式 | 説明 |
|---|---|
|
distinct {Variadic | AnyExpression} |
複数の式の一意の和集合を生成します。 |
|
except {Iterable, Variadic | Iterable} |
2 つのシーケンスの差集合を生成します。 |
|
first {Number, Variadic | Iterable} |
各式の最初の結果を返します。 |
|
groupBy {Iterable, Optional | Selector} |
Group search results by a specified @selector | Hints: ExpandSupported |
|
intersect {シグネチャなし} |
2 つのシーケンスの交叉を生成します。 |
|
last {Number, Variadic | Iterable} |
各式の最後の結果を返します。 |
|
map {イテラブル, 値} |
式の結果をマッピングし、変数を使用して新しい式を形成します。 |
|
select {シグネチャなし} |
どの値およびプロパティを取るか選択して、新しい結果を作成します。 |
|
sort {シグネチャなし} |
条件に基づいて式の結果をソートします。 |
|
union {Variadic | AnyExpression} |
複数の式の一意の和集合を生成します。 |
集合のフィルタリング
| 式 | 説明 |
|---|---|
|
eq {Iterable, Selector, Literal | QueryString} |
値が等しい検索結果を保持します。 |
|
gt {Iterable, Selector, Literal | QueryString} |
より大きな値を持つ検索結果を保持します。 |
|
gte {Iterable, Selector, Literal | QueryString} |
値がより大きいか等しい検索結果を保持します。 |
|
lw {Iterable, Selector, Literal | QueryString} |
値がより小さい検索結果を保持します。 |
|
lwe {Iterable, Selector, Literal | QueryString} |
値がより小さいか等しい検索結果を保持します。 |
|
neq {Iterable, Selector, Literal| QueryString} |
異なる値を持つ検索結果を保持します。 |
|
where {Iterable, Text | Selector | QueryString} |
式が有効でない検索結果を除外します。 |
数学
| 式 | 説明 |
|---|---|
|
avg {Selector, Variadic | Iterable} |
各式の平均値を求めます。 |
|
count {Variadic | Iterable} |
式の結果の数を数えます。 |
|
max {Selector, Variadic | Iterable} |
各式の最大値を求めます。 |
|
min {Selector, Variadic | Iterable} |
各式の最小値を求めます。 |
|
sum {Selector, Variadic | Iterable} |
各式の合計値を計算します。 |
ユーティリティ
| 式 | 説明 |
|---|---|
|
alias {Iterable, Text | Selector | Iterable} |
Assigns an alias to an expression. | Hints: AlwaysExpand |
|
constant {Literal | Function} |
各式の最初の結果を返します。 |
|
format {Text | Selector, Variadic | AnyValue} |
引数を文字列に変換し、結果を書式設定できるようにします。 |
|
print {Text | Selector, Variadic | Iterable} |
式の結果をコンソールに表示します。 |
|
query {シグネチャなし} |
ヒント: ExpandSupported |
|
random {Variadic | Iterable} |
各式の結果をランダムに選択します。 |
|
set {Variadic | Iterable} |
任意の式から要素の集合を返します。 |
|
text {シグネチャなし} |
任意の式のテキストをリテラル文字列に変換します。 |
関数 (アルファベット順)
alias
alias{set, aliasName} -> {集合の各要素に aliasName が割り当てられます}
alias{set, formatString} -> {集合の各要素に formatString から計算されたエイリアスが割り当てられます}
この関数は、式に効果的に別名 (エイリアス) を割り当てます。これは、“as” キーワードを使うのと同じです。エイリアスの使用法 も参照してください。
例:
count{t:material as material} は以下と同等です。
count{alias{t:material, material}}
例:
要素 1, 2, 3 に “number” というエイリアスを割り当てます。
alias{[1, 2, 3], 'number'}
例:
1, 2, 3 にフォーマット文字列から動的に計算されたエイリアスを割り当てます。
alias{[1,2,3], 'number @value}'}
avg
avg{selector, sets...} -> {Average of selector value in each set}
avg{set...} -> {Average of @value in each set}
パラメーターとして渡された各集合のそれぞれの要素の平均値を求めます。
例:
avg{[1,2,3,4, 5,6], [1, 1, 1], []} -> {3.5, 1, 1}
例:
avg{@size, t:texture, t:material} -> {1100576, 3618}
constant
constant{value} -> {constant value}
この関数は、値を定数リテラル値 (数字、文字列、ブーリアン) に変換しようとします。これは、いくつかの関数でパラメーターの型の曖昧さをなくすために使用されます。
例:
first{constant{5}, t:material}
count
count{sets...} -> {count of each set}
パラメーターとして渡された各集合の結果の数を数えます。
例:
count{t:texture, t:material} -> {359, 194}
例:
“assets” (アセット) という名前のインデックスから、アセットをタイプ別にグループ化し、そのアセットグループごとにアセットを数えます。最も大きな 5 つのグループを示します。
first{5, sort{count{...groupBy{a:assets, @type}}, @value, desc}}
distinct
distinct{sets...} -> {すべての集合内のすべての一意の要素の統合集合}
Distinct は、パラメーターとして渡されたすべての集合のすべての要素の集合を作成します。union と同様に、重複する要素は保持されません。
例: この例では、重複が削除されることを示しています。
distinct{[1,2,3], [3,4,5]} -> {1,2,3,4,5}
例:
distinct{*.mat, t:shader} -> {プロジェクト内のすべてのマテリアルとシェーダー}
例:
“project” という名前のインデックス内の各アセットの @type を選択し、各タイプの 1 つのアセットを保持します (アセットの @value に従って重複が計算されるため)。
distinct{select{a:project, @type}}
eq
eq{set, value} -> {value と等しいすべての要素}
eq{set, selector, value} -> {value と等しいすべての selector 値}
指定された値に等しいものを除外して、要素の集合をフィルタリングします。
例:
eq{[2,4,5,6,4,3], 4} -> {4,4}
これは、以下と同等です。
where{[2,4,5,6,4,3], "@value=4"}
例:
#width のシリアル化されたプロパティが 256 のテクスチャをすべて検索します。
eq{t:texture, #width, 256}
これは、以下と同等です。
t:texture #width=256
except
except{set, sets...} -> {新しい要素の集合}
Except は、パラメーターとして渡されたどの集合にも含まれないすべての要素の集合を作成します。
例:
except{[1,2,3,4,5], [2,3], [5], [6]} -> {1,4}
例:
except{t:prefab, t:prefab ref=select{t:texture, @path}}
first
first{sets...} -> {各集合の最初の要素}
first{count, sets...} -> {各集合の最初の count 要素}
First は,パラメーターとして渡された各集合で最初の要素の集合を返します。count がパラメターとして渡された場合、各集合の最初の count 要素を取ります。
例:
first{[3, 4,5], [9, 28, 3]} -> {3,9}
例:
first{3, [9, 28, 3, 4, 6, 7, 8, 9], [1, 2, 3, 4, 5, 6, 7]} -> {9, 28, 3, 1, 2, 3}
例:
プロジェクト内のすべての .fbx ファイルをサイズの降順でソートし、最大の 3 ファイルを表示します。
first{3,sort{*.fbx, @size, desc}}
format
format{expression} -> {値を文字列に変換する項目の集合}
format{formatString, expression} -> {書式文字列を適用して値が設定される項目の集合}
format は 2 つの方法で使用できます。式の引数が 1 つだけの場合、項目の現在の @value を文字列表現に変換しようとします。
format を書式文字列と共に使用する場合、書式文字列内のすべてのセレクターを項目の選択された値で置き換え、この書式設定された文字列をアイテムの @value に設定します。
例:
print{format{"value=@value", [1,2,3,4]}} は、コンソールウィンドウに [“value=1”, “value=2”, “value=3”, “value=4”] と出力します。
groupBy
groupBy{set, selector} -> {セレクターによってグループ化された項目の複数の集合}
例:
プロジェクト内の各タイプのアセット数を数えるには、groupBy 関数と Expand Operator を組み合わせると、セレクターに従ってアイテムを自動的にグループ化することができます。以下の例では、同じタイプの項目の集合が作成されます。Expand Operator を使うと、この項目の集合を同じタイプの複数の集合に拡張することができます。
count{...groupBy{a:assets, @type}} -> {numberOfAssetType1, numberOfAssetType2, .. numberOfAssetTypeN}
gt
gt{set, value} -> {value より大きい全ての要素}
gt{set, selector, value} -> {selector の値が value より大きい全ての要素}
指定された値より大きい要素を残すように、要素の集合をフィルタリングします。
例:
gt{[2,4,5,6,4,3], 4} -> {5,6}
gte
gte{set, value} -> {value より等しいか大きい全ての要素}
gte{set, selector, value} -> {value より等しいか大きいセレクターを持つ全て}
指定された値より大きいか等しいものを残すように、要素の集合をフィルタリングします。
例:
gte{[2,4,5,6,4,3], 4} -> {4,5,6,4}
intersect
intersect{sets...} -> {すべての集合に含まれる要素}
intersect{sets..., selector} -> {selector の値がすべての集合に含まれる要素}
intersect は、@value がすべての集合に含まれる要素で新しい集合を作成します。パラメーターとして selector (セレクター) が渡される場合、セレクターの値が要素の比較に使用されます。
例:
intersect{[1,2,3,4,5], [3, 5], [6, 3]} -> {3}
例:
サイズが 4000 バイトより大きいテクスチャをすべて探し出し、パスに “rock” という単語が含まれるテクスチャすべてと intersect (交叉) します。
intersect{t:texture size>4000, t:texture @path:rock}
last
last{sets...} -> {各集合の最後の要素すべて}
last{count, sets...}.-> {各集合で最後の count 要素}.
last は,パラメーターとして渡された各集合内で最後の要素の集合を返します。count をパラメーターとして渡すと、各集合の最後の count の要素を取ります。
例:
last{[3, 4,5], [9, 28, 3]} -> {5, 3}
例:
last{3, [9, 28, 3, 4, 6, 7, 8, 9], [1, 2, 3, 4, 5, 6, 7]} -> {7,8,9,5,6,7}
例:
プロジェクト内のすべての .fbx ファイルをサイズの昇順で並べ替え、最後の 3 つを取ります。
last{3,sort{*.fbx, @size}}
lw
lw{set, value} -> {value より小さいすべての要素}
lw{set, selector, value} -> {selector の値が value より小さいすべての要素}
指定された値より小さい要素を残して、要素の集合をフィルタリングします。
例:
lw{[2,4,5,6,4,3], 4} -> {2,3}
lwe
lwe{set, value} -> {value より等しいか小さいすべての要素}
lwe{set, selector, value} -> {value より等しいか小さいセレクターを持つすべて}
指定された値より小さいか等しいものを残すように、要素の集合をフィルタリングします。
例:
lwe{[2,4,5,6,4,3], 4} -> {2,4,3,4}
map
map{set, <string containing selectors to replace>}
map 演算子は、検索式 を表現する関数的な方法です。この演算子は、式の結果をマッピングして、変数を使った新しい式を作成します。
以下の例
map{t:texture, t:prefab ref=@id} -> {t:prefab ref=<textureId1>} {t:prefab ref=<textureId2>} ... {t:prefab ref=<textureIdN>}
は、t:texture が返すテクスチャそれぞれに対して、 t:prefab ref=@id のクエリを実行します。
これは以下を実行するのと同じです。
{t:prefab ref={t:texture}}
max
max{sets...} -> {各集合における最大値の要素}.
max{selector, sets...} -> {各集合における最大 selector 要素}
パラメーターとして渡された各集合について、最大値 @value を検索します。パラメーターとして selector (セレクター) が渡される場合、 最大の @selector 値をもつ要素を検索します。
例:
max{[1,2,3,4,5,6], [2,4,5]} -> {6, 5}
例:
最大の .png と最大の .jpg ファイルを見つけます。
max{@size, *.png, *.jpg} -> {<largest .png file>, <largest .jpg file>}
min
min{sets...} -> {各集合における最小値の要素}
min{selector, sets...} -> {各集合における最小 selector 要素}
パラメーターとして渡された各集合について、最小値 @value を検索します。パラメーターとして selector (セレクター) が渡される場合、 最小の @selector 値をもつ要素を検索します。
例:
min{[1,2,3,4,5,6], [2,4,5]} -> {1, 2}
例:
一番小さい .png ファイルと一番大きい .jpg ファイルを探します。
min{@size, *.png, *.jpg} -> {<smallest .png file>, <smallest .jpg file>}
neq
neq{set, value} -> {value と等しくないすべての要素}
neq{set, selector, value} -> {value と等しくないすべてのセレクター値}
指定された値と等しくないものを残すように、要素の集合をフィルタリングします。
例:
neq{[2,4,5,6,4,3], 4} -> {2,5,6,3}
print(FormatString | selector, set)
print は、フォーマット文字列 (またはセレクター) と項目の集合を受け取り、各項目の書式設定された結果をコンソールに表示します。これは、ある項目の値をデバッグするのに便利です。
プロジェクトで、以下の式でテクスチャとそのパスをサーチウィンドウに返し、コンソールウィンドウに出力します。
print{'path=@path', t:texture}
例:
print{@value, [1,2,3,4]} would print [1,2,3,4] in the Console window.
query
query{value} -> {query expression}
この関数は、値をクエリ式に変換しようとします。これは、一部の特定の関数でパラメーターの型の曖昧さをなくすために使用されます。
例:
count{t:material} は以下のものと同じです。
count{query{t:material}}
random
random{sets... -> {各集合に含まれるランダムな要素}
パラメーターとして渡された各集合から取り出したランダムな要素から集合を作成します。
例:
random{[1,3,5], [6,4,2]} -> {3, 2} は各集合のランダムな結果を返します。
select
select(<set>, selectorForLabel, selectorForDesc, otherセレクターs...)
select は、新しい検索の集合を作成し、元の検索の集合からプロパティを抽出したり変換したりする関数です。
select 関数の第 2 パラメーター (selectorForLabel) は、選択された値を新しい項目のラベルに割り当てます。
3 番目のパラメーター (selectorForDesc) は、選択された値を新しい項目の説明に割り当てます。
select 関数の最後のセレクターは、項目の値も指定します。
例:
プロジェクトでテクスチャを検索する場合、select を使用すると、ラベルがパスで説明がテクスチャのサイズとなる項目の集合が生成されます。
select{t:texture, @path, @size}
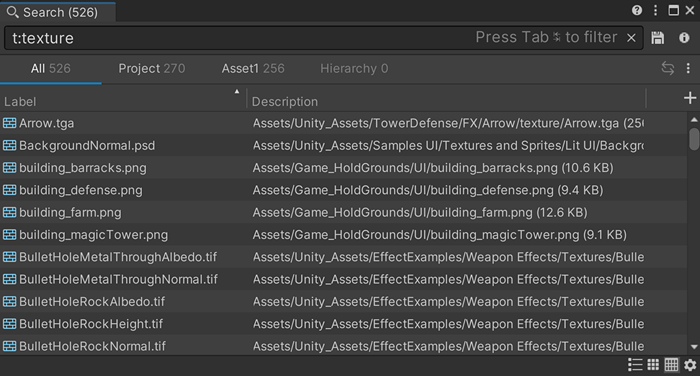
select 構文の最後のセレクターは、その項目の値も設定します。select{t:texture, @path, @size} の例では、@size が検索項目の @value にもなることを意味しています。テーブルビューに切り替えると、検索式がラベルを置き換え、説明文が値を設定する様子を確認することができます。
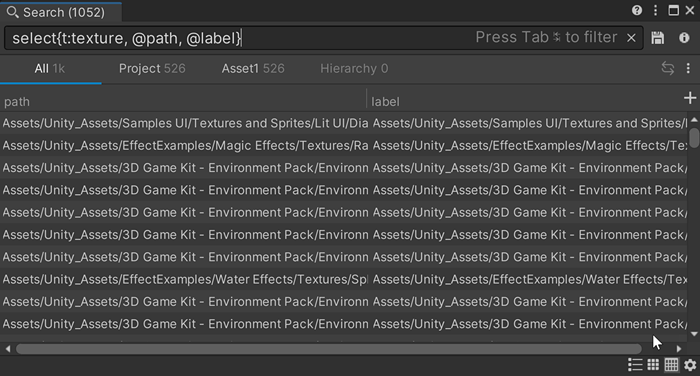
select 関数のセレクターは、関数そのものになることもできます。これらの関数内のセレクターは、処理中の検索項目に応じて評価されます。
例:
select{t:texture, @path, count{t:prefab ref=@id}}
- プロジェクト内の各テクスチャに対して、新しい検索項目を作成します (
t:texture) - そのラベルは、テクスチャ の
@path(@path) と同じです。 - また、 その説明はそのテクスチャを参照するプレハブの数に等しくなります (
count{t:prefab ref=@id})。この例では、@idは各テクスチャアイテムのSearchItem.idを参照します。
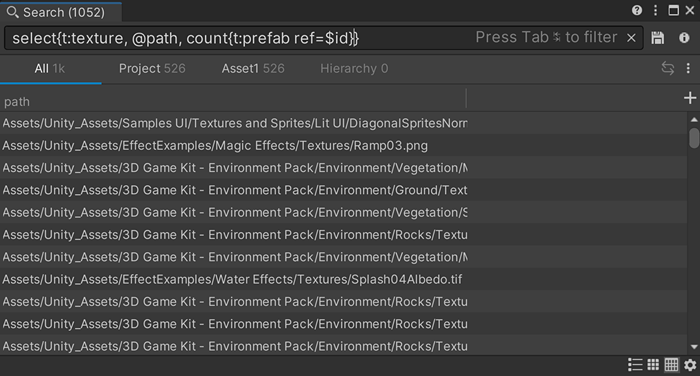
エイリアス演算子を使用すると、検索項目フィールドにプロパティ値を割り当てることができます。
例:
print{"@pow", select{t:script, @path as pow}}
これは、検索項目から @path プロパティを抽出し、select 関数で作成した新しい検索項目内の pow という検索項目フィールドに割り当てています。
set
set{sets...} -> {すべての集合のすべての要素の集合}
パラメーターとして渡されたすべての集合に含まれるすべての要素からなる集合を作成します。これは、“[set, of , element]” と同じです。
例:
set{[1,2,3], [4,5,6]} は以下と同等です。
[[1,2,3], [4,5,6]] は以下と同等です。
[1,2,3,4,5,6]
sort
sort{set, selector} -> {セレクターの値に従って昇順にソートされたアイテムの集合}
sort{set, selector, desc} -> {セレクターの値に従って降順にソートされたアイテムの集合}
セレクターの値に従って、集合の項目を降順または昇順に並べ替えます。
例:
この集合を昇順 (小から大へ) に並べ替えます。
Sort{[4,2,7,5,8,1,9], @value} -> {1,2,4,5,7,8,9}
例:
この集合を降順 (大から小へ) に並べ替えます。
sort{[4,2,7,5,8,1,9], @value, desc} -> {9,8,7,5,4,2,1}
例:
プロジェクトに含まれるすべてのテクスチャを、@size に従って降順で並べ替えます。
sort{t:texture, @size, desc}
sum
sum{sets...} -> {各集合に含まれるすべての要素}
sum{selector, sets...} -> {各集合に含まれるすべての要素}
パラメーターとして渡された各集合の各項目の合計 @value を求めます。パラメーターとして selector (セレクター) が渡される場合、各集合の各要素の合計 @selector 値を求めます。
例:
sum{[1,2,3,4,5,6], [2,4,5]} -> {21, 11}
例:
プロジェクト内のすべてのテクスチャ @size の合計を求めます。
sum{@size, t:texture}
text
text{expression} -> {"式のテキスト"}
式から文字列を作成します。これは、 "" や ‘’ 区切り文字を使うのと同じです。
例:
[text{hello}] は以下と同じです。
["hello"] または [‘hello’]
union
union{sets...} -> {すべての集合のすべての一意の要素を統合した集合}
union は、パラメーターとして渡されたすべての集合のすべての要素の集合を作成します。distinct のように、要素の重複はありません。
例:
この例では、重複が削除されることを示しています。
union{[1,2,3], [3,4,5]} -> {1,2,3,4,5}
例:
union{*.mat, t:shader} -> {プロジェクト内のすべてのマテリアルとシェーダー}
where
where{set, filterString | selector} -> {フィルタリングされた要素の集合}
where は、セレクターまたはセレクターの使用法と演算子 (>, ==, …) を含むセレクターか文字列を受け取って、集合の要素をフィルタリングし、新しいフィルタリングされた集合を返す、一般的なフィルタリング関数です。
例: 数値に応じて数をフィルタリングします。
where{[1,2,3,4,5,6,7,8,9,10], '@value>4 and @value<9'} -> {5,6,7,8}
例:
単語 effect を含むすべてのオーディオクリップを検索します。
where{t:AudioClip, @path:effect}